
NCDC and NASA complain that the US temperature record is problematic, but this is complete BS. I tried splitting the 1200 HCN stations into two nearly evenly sized groups, those whose station number ends in 0-4 and those whose station number ends in 5-9. There is no overlap in the groups and group placement is for all intents and purposes random.
As you can see, they produce almost identical trends, indicating that the US surface temperature record is excellent, and adjustments are unnecessary and unwanted. Trying to adjust individual stations is scientific madness.
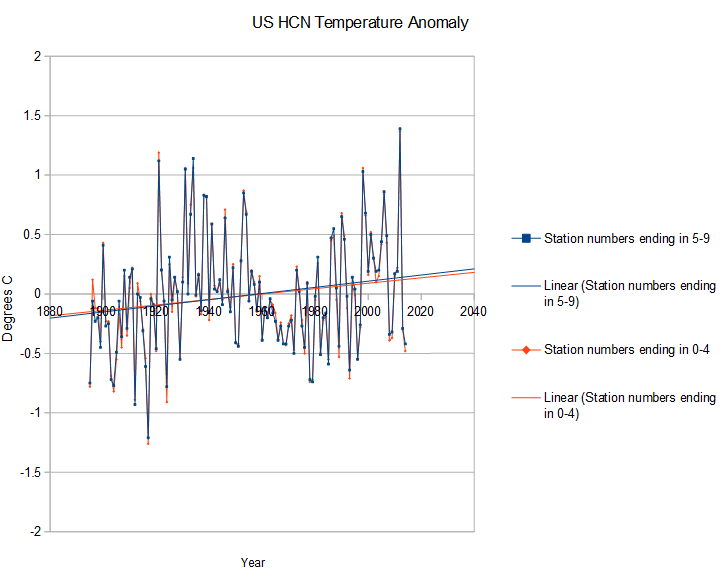
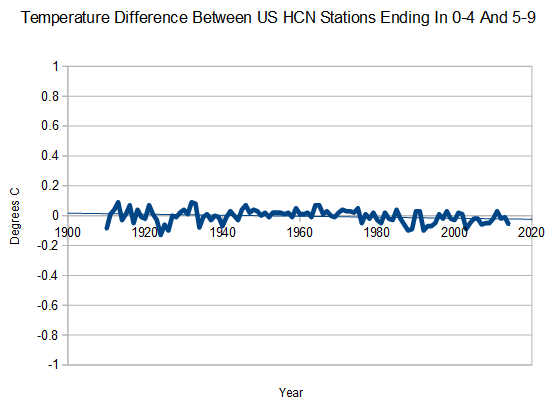

Truth is like poison to climate alarmists. Yet they call us “deniers”!
Tony…….
If you present them with your findings, will they, or do the respond??
“The algorithm is working as designed”
Of course “The algorithm is working as designed”
https://www.youtube.com/watch?v=zILOW5_OwWI
When they claim tempurature records are problematic, they mean problematic for their agenda. As you demonstrate, the data is inherently accurate and consistent.
What would it look like if you were to take ten groups (0 – 9) and compare the high and low outliers to the average of the remaining eight groups?
Questions: When you present your temperature plots are you using raw USHCN data? If so, do you correct for obvious errors in the records (e.g. Tmin = -100F or similar)? TOBS? Perhaps this is addressed in a previous post. Thanks.
TOBS posts:
https://stevengoddard.wordpress.com/?s=tobs
Thanks Gail.
Now do Odd v Even last number graphs.
I don’t think this particular analysis is very convincing. If half the sites are reporting too cold, you would expect them to be evenly divided between any two random groups.
Something like Principle Component Analysis of temperature anomalies would be more convincing. Or do a statistical outlier test on all of the stations, and show that the fraction of outliers is very low or the composition of the outliers does not reflect a systematic bias.
Go for it. Will you post your analysis here?
Why would you think the sites are reporting too cold?
Most of the bias I can think of cause warmer temperatures not colder. Such as Urban Heat Island Effect, or a Dirty Stevenson screen.
Steve has already looked at Tobs
Are you thinking of a Stevenson screen filling up with snow? Snow is a decent insulator, hence igloos.
The Stevenson Screen came into use in the late 1860s.
You wouldn’t know it,
& you couldn’t possibly correct for it.
It would be pretty easy to say that you knew it, & that you had a system of correcting for it though, because it wouldn’t be disprovable either.
Hey KTM! I think you are correct that this particular analysis –taken by itself — is not convincing. That phrase I inserted, “taken by itself”, is important though. Lord knows, there are enough other reasons to mistrust the official adjustments!
Tony! Help me out, please! Maybe I am having a low IQ day, but it seems like I must be missing the point. I agree that any adjustments need to be specific and justified for clear and obvious reasons. The present reiterative procedure they have where (as near as I can tell) an algorithm recurringly adjusts the past — and again re-adjusts the already adjusted past based on more current temperatures — and then again re-re-adjusts the already re-adjusted past, all based on some assumed standards of data self consistency — is just madness!
Still, I do not see what is demonstrated by creating two random groups and showing that they make the same pattern. Can you explain your point again? I am just not seeing it.
Thanks, Tony!
It indicates that there are consistent patterns across the data set.
If you do the same exercise with global GHCN stations, you get a completely different result with each random grouping. Meaning the global temperature record is total BS.
Ah! OK, the “consistent pattern” I could see; of course that does not prove accuracy, only consistency. One could still have a consistent pattern even if there were systematic errors throughout the data — as long as the errors were relatively evenly spread.
What you say about the GHCN record really surprises me though! If you get different results with truly random groups (assuming your groups are reasonably large) then yes, that indicates a major problem.
So-called “climate science” is so poorly done that it is difficult to know which part to spit on first. The entire process of taking averages of averages of averages — all based on a daily maximum and minimum without any information on durations of warm or cold is crazy. Then perform a secret algorithm that removes and alters what little information is left…
Just a thought… maybe it would make more sense to have a large mass around your thermometer to create a roughly 24 hour thermal lag. One reading a day would more closely show average temperature than averaging a momentary high with a momentary low.
The global temperature record is complete crap. It astonishes me that anyone would have the audacity to claim that they know what long term global trends are based on it.
If I recall the reasoning for ‘adjustments’ correctly, one of the reasons for ‘adjusting’ past records was because SOME of the data was taking incorrectly. Thermometers not calibrated, observations taken at the wrong time of day, no Stevenson screen.
Tony is looking at the data from before 1900. If some of the data was taken incorrectly and if the problems were all corrected simultaneously that would show as a sudden jump or dip in the curve.
If, as would be typical, a block of stations, say a state or a few states within a region were corrected at a time, then you would see the two curves diverge from each other since the effect would not be random.
However all you see is two nicely matched curves that match the ocean oscillations and a slight warming coming out of the little ice age or a slight warming due to UHI.
What ever errors there are they are random and this analysis shows no obvious errors that need ‘adjustments’
Taken with Tony’s look at Tobs: https://stevengoddard.wordpress.com/?s=tobs
And his look at UHI: https://stevengoddard.wordpress.com/?s=uhi
There is NO scientific justification for continually ‘adjusting’ the data.
From my personal experience there certainly is not any reason for the new state of the art station at a rural airport to be adjusted up by 2 to 3 F every day. Especially when that adjustment means a reading above freezing and rain while in the real world my stock tanks develop two inches of ice and my pastures are covered by 4 inches of snow. The station is within walking distance.
Hey Gail! Thanks for the input! “If, as would be typical, a block of stations, say a state or a few states within a region were corrected at a time, then you would see the two curves diverge from each other since the effect would not be random.”
Are you sure about that? I think it would depend on the nature of the error and the size of the random block. Suppose that there were 500 stations east of the Mississippi and 1000 to the west. Suppose all of the east stations measure 2 degrees too hot. You average everything and get a certain curve. Now divide the data into two random groups. Each group has roughly 500 western stations and roughly 250 eastern stations. Wouldn’t you still get pretty much the same curves from each as you did from the total group? If the errors (even large errors) are spread out equally into each new group, doesn’t that just recreate the original curve?
Am I still missing something? This is all done to raw data, correct? The two groups are truly random, correct? Be gentle if I am being dense!
Are the station numbers assigned geographically? Is the 0-4 group all in one part of the country and the 5-9 group in the other part?
No, the last digit has no geographical or other significance
Jason,
My thinking is you have 1200 stations. Say 100 stations a year are ‘corrected’ That would be changes over 12 years or 12 changes. The changes might not show up, but because they are not random changes AND because they are not a one-off, I think the probability (link) is you would see divergence in the data especially if the changes had a great effect on the temp.
It certainly isn’t a conclusive test but it ‘lends weight’ especially since there are no big discontinuities indicating the changes were done all at one time. Also there is all the other work Tony has done.
Everything I have seen says KEEP your mitts OFF the data!” If you think there is a problem then widen the error bars like any real scientist would!
Ernest Beck provides an excellent example of how the data should be represented.
http://www.biomind.de/realCO2/bilder/CO2back1826-1960eorevk.jpg
Hey Gail and Tony! Again, thanks for your input. “Everything I have seen says KEEP your mitts OFF the data!” If you think there is a problem then widen the error bars like any real scientist would!”
I feel the same about the data — and all the work, especially what Tony has done here at this site, seems to support that view. The major governmental outlets for “climate scientists” have been consistently and very, very systematically (IMHO fraudulently) altering the data and warming any trends.
I won’t drag this topic out any more (and I appreciate both of you and your efforts to clarify this for me) but I honestly do not see that this particular post illustrates data quality, either good or bad. It just seems to me that if you take a large data set and divide it into two equal sized but random parts, that each half will still have the same average as the entire set, even if there is erroneous data present. Only in a data set that has a quite small number of erroneous elements which are VERY far from the average will the two halves show significantly different averages. Anyway, that is how I see it — but I may be wrong!
Jason, look at the link on probability. Once you start modernizing** you get into N! at that point the probability that you are not going to see something happen in the split data goes down.
I am not a statistician so maybe William M. Briggs could give a more definitive answer.
http://wmbriggs.com/
** That is taking it that the modernization was not done all at one time.
Hey Gail! Yes, thanks of the link, and I am familiar with factorials and permutations.
You say: “Once you start modernizing** you get into N! at that point the probability”
Maybe this is the point of confusion. I do not see how this post deals with “modernizing” data. As Tony describes what he did, it was simply to take the HCN data set (he does not say whether it is the raw or the altered) and split it into two more-or-less random halves. He then compared the two halves, and each half showed pretty much the same graph as the other half. My understanding is that he did not compare raw data to altered data, or data altered in 1997 to data altered in 2014, or one geographic area to another geographic area. Unless I just read things wrong, he compared one random half of a large data set with the remaining half of the exact same data set.
Let’s take a coin toss analogy. Assume a fair coin. Make 10,000 tosses. You will almost certainly NOT have 50% heads — but it will be quite close! Additionally, if you divide that sequence of tosses into two random halves of 5,000 each, each half will again be very close to 50% heads. It is true that you could potentially have a big difference, but statistically speaking, much deviation from 50% is unlikely. No big surprise there.
Now alter that data set. Erase the results of 5,000 tosses, either at random or in any group you wish, ie, throw out the first 5,000, or the last 5,000, or maybe all the odd numbered tosses, choose however you wish. In fact, if you like, you can throw out 4,000 tails and 1,000 heads. Replace those 5,000 with nothing but heads. Your data set (very much altered now) will now show somewhere between 50% and 100% heads. If you did, in fact, choose to erase 5,000 data points at random, your new set will be near 75% heads. Take your new altered data set and divide it into two random halves. Assuming that your two new half sets really are pulled randomly from your altered complete set, each half will still the same percentage (whatever that is) as the other half. If you removed random throws, then each half will be close to 75%, other wise each half will show the same number somewhere between 50% to 100%. Assuming that the two halves are picked at random from the total set, the fact that both halves agree does not tell you very much at all. The data set — even though it is complete garbage as far as accurately reporting the results of your original 10,000 tosses — still has two consistent halves. The only way the two halves could be significantly different from each other is if 1) you just happened by extreme unlikelihood (one in a thousand? one in a million?) to get a whole lot of heads in one random half and a whole lot of tails in the other remaining half, or 2) if you were dealing with a data set that instead of two simple values had data in a large range, and at the same time had only a small number of data points with values way out at the ends of the range. (For an extreme example, suppose you had 9,999 points that had a value between 0 and 1, but one point with a value of 200.)
My reading of Tony’s exercise in this post is that he divided up a large data set into two random halves and compared each half to the other. He got the same results in the two halves. I really am not trying to be dense here — but I still do not see how that illustrates data quality. Again, I agree that the temperature data in the real world of fraudulent data changes has been tortured, I just do not understand how this post gives us insight into data quality.
Am I misunderstanding the mechanics of what Tony did here?
(Gail, feel free to ignore me if you think I am being too dense to deal with…) 🙂
It doesn’t prove that there is no systematic bias.It does prove that the measurements are being taken in a consistent fashion with reliable instruments.
Jason I am thinking about what happens to the method of measurement over time. I am also assuming some sort of organization with some sort of planning and direction. (Yeah I know we are talking fumble footed bureaucrats.)
You start in 1880 with a set min-max thermometers hanging from a tree. ===> a whitewashed Stevenson screen ===> a latex painted Stevenson screen ===> a digital thermistor instead of a min-max thermometer. OH and according to WUWT It seems NOAA has ‘de-modernized’ the official Death Valley station to use older equipment to make a record more likely
So leaving out changes to the landscape + Tobs there were changes in the equipment used. These changes most likely did not happen simultaneously across all stations but more probably in batches yet despite this the data is consistent within 0.1C.
I am taking this from work done by Anthony Watts:
http://wattsupwiththat.com/2008/01/13/stevenson-screen-paint-test-plot/
http://wattsupwiththat.com/2013/06/29/aging-weather-stations-contribute-to-high-temperature-records/
You can plug “Stevenson Screen Paint Test” into Anthony’s search engine for more info.
What are they worried about anyway? In 15 years time, after “adjustments”, we’ll find out that it isn’t as hot now as we think it is. We’re just too stupid in the present to read thermometers correctly.
The “adjustments” are driven by politics and greed. They are intended to produce a global warming signal where there isn’t one, thereby perpetuating the AGW fraud while boosting the budgets of NCDC and GISS and ingratiating its directors with their political bosses. In the meatime, the taxpayers are scammed out of hundreds of billions of dollars in a wasteful and assinine crusade against an imaginary global warming bogeyman.
The battle of planet earth against global climate change is the sort of stuff that belongs in an H.G. Wells science fiction novel. Unfortunately, the world is full of gullible people who believe anything the government tells them — and they are allowed to vote.