
- Download HIDING.zip to a directory where you have at least 400MB disk space. It contains the entire US temperature record. The python source code is here.
- Unzip it
- cd to the HIDING\release directory in a command prompt window.
- Run it : ghcn.exe US.txt date=0814
(The latest ghcn.exe executable is here. Replace the one in the HIDING\release directory with that.)
It will look like nothing is happening, but after a few minutes when the temperature data set is processed, this window will pop up.
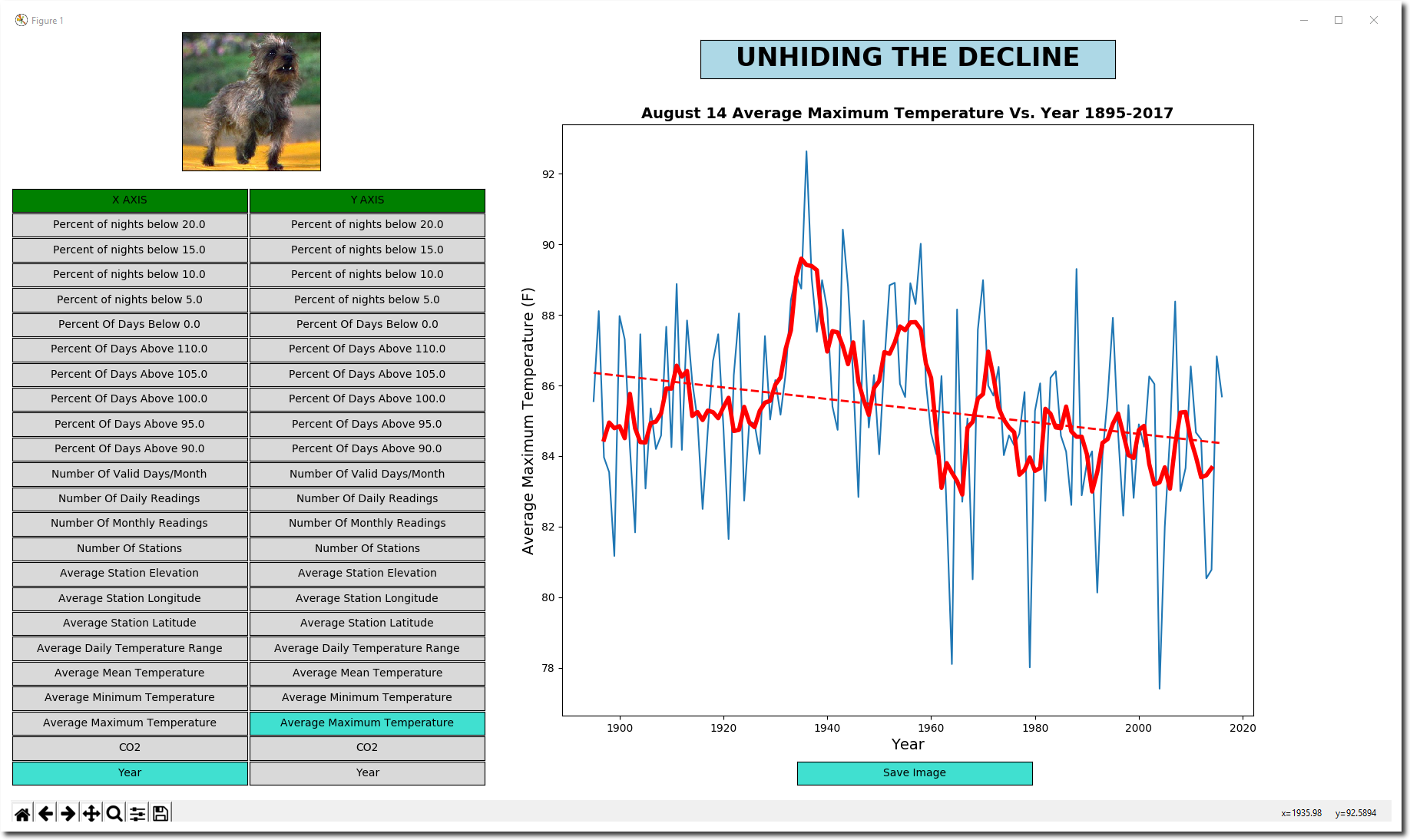
You can generate hundreds of different graph types very quickly by simply clicking on an X-axis option (left column) and Y-axis option (right column) . Click on the “Save Image” button to create a .png file, which is in the same directory you ran ghcn.exe from. It also generates a csv file in that directory with all of the stats.
Other command line options include :
- spring
- fall
- month=[1-12]
- date=[mmdd]
- first_year=[yyyy]
- last_year=[yyyy]
- target_type=[MIN/MAX/BOTH]
- target_min=[temperature F] (used for stats)
- target_max=[temperature F] . (used for stats)
- state=[AZ/AK/CO…..]
- required_range=[YYYY:YYYY] . ( station must have been active in both years)
The algorithm is very simple.
- Average all daily temperature records for one station for one month (that is how NOAA organizes them)
- Average all of the 1200 station averages for that month
- Repeat for all 12 months, and all years from 1895 to the present.
That is it. The algorithm is an improvement over my previous software, which lumped all daily data from all stations together per month. That unfairly weighted stations which reported more days relative to stations which reported fewer days.
If you find any bugs, let me know! There may well be some. I just started this project last weekend.
To get the latest US.txt from NOAA, you can run this script from a Mac/Linux/Cygwin/Mingw command prompt. That is why I included the US.txt in the zip file.
