
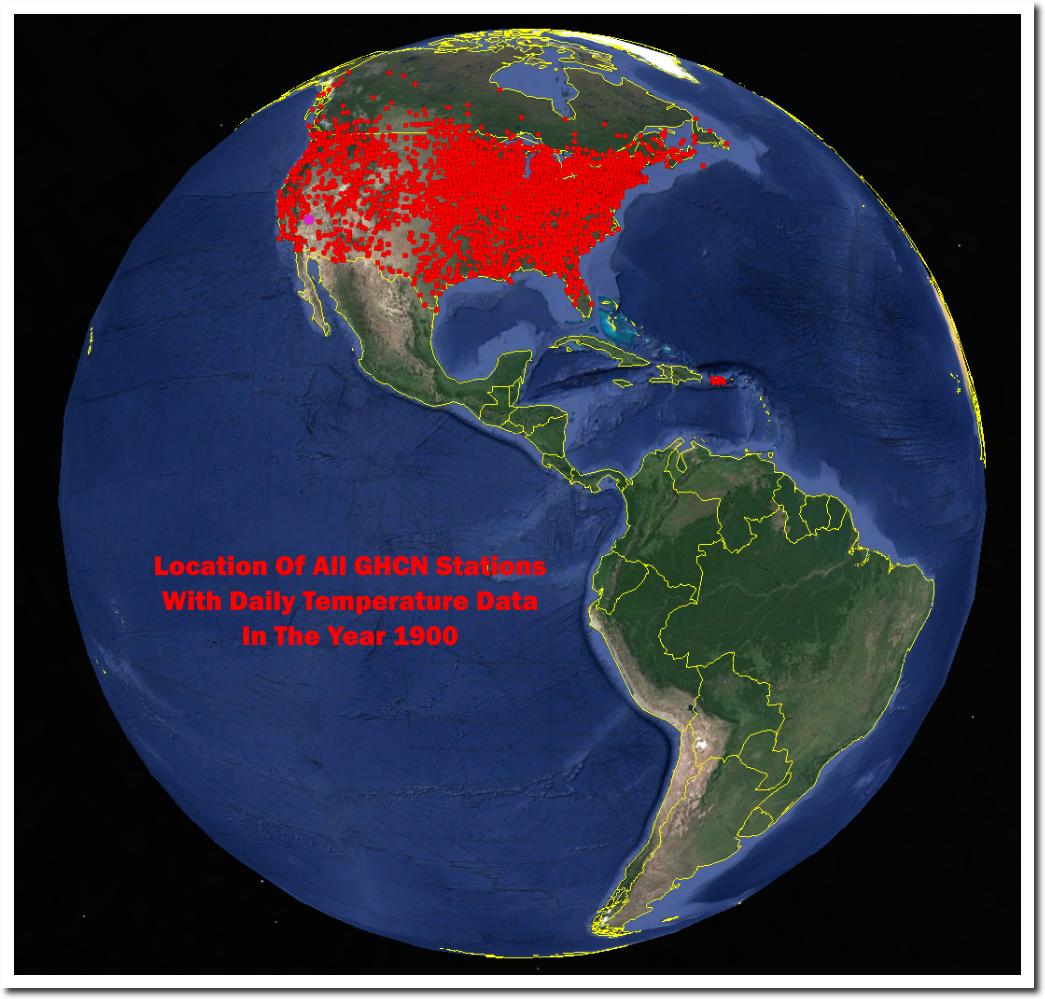
ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/daily/figures/station-counts-1891-1920-temp.png
NOAA has no daily temperature data from Central or South America, or most of Canada from the year 1900, But they claim to know the temperature in those regions very precisely. Same story in the rest of the world.
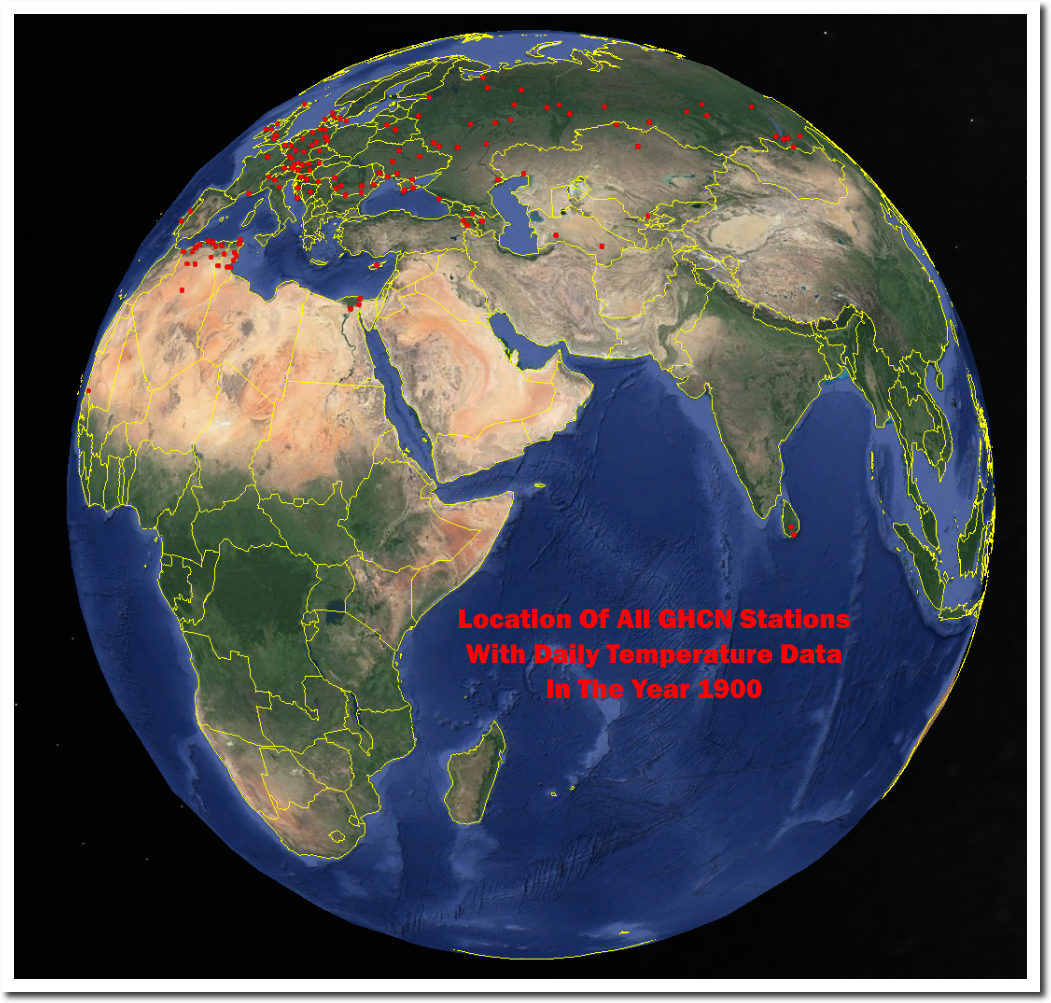
Despite not having any data, all government agencies agree very precisely about the global temperature.
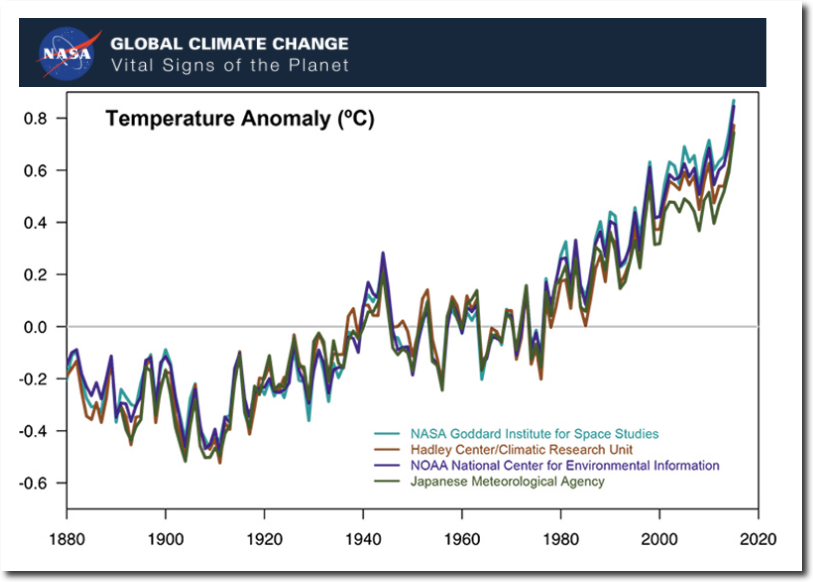
Climate Change: Vital Signs of the Planet: Scientific Consensus
The claimed global temperature record is completely fake. There is no science behind it. It is the product of criminals, not scientists. This is the biggest scam in history.

{kind=link}