
All large data sets contain measurement or calculation errors. Unless there is some specific reason to believe the data is skewed due to an external trend (like UHI) people normally assume the errors are random and expect them to cancel out. Many fields of science and engineering depend on this principle, including nuclear weapons design.
For example, there is just as likely to be missing temperature data in January as July, so making up fake temperatures for missing dates serves no purpose and only corrupts the data.
When climate scientists start making adjustments, confirmation bias sets in. They look for problems which cause mismatches vs. their theory, and ignore problems which would work against their theory if corrected.
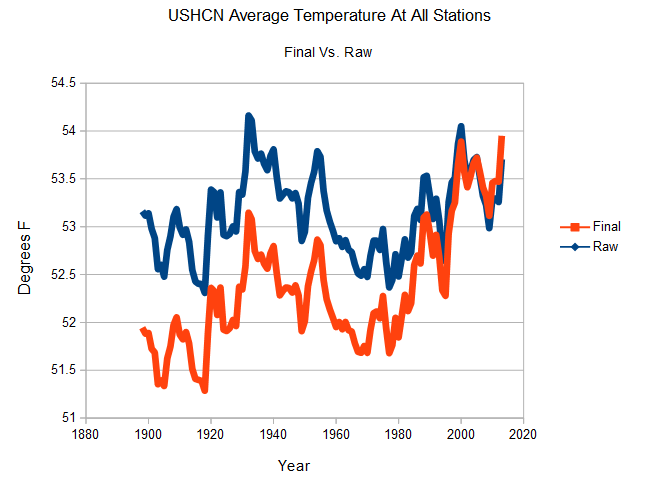
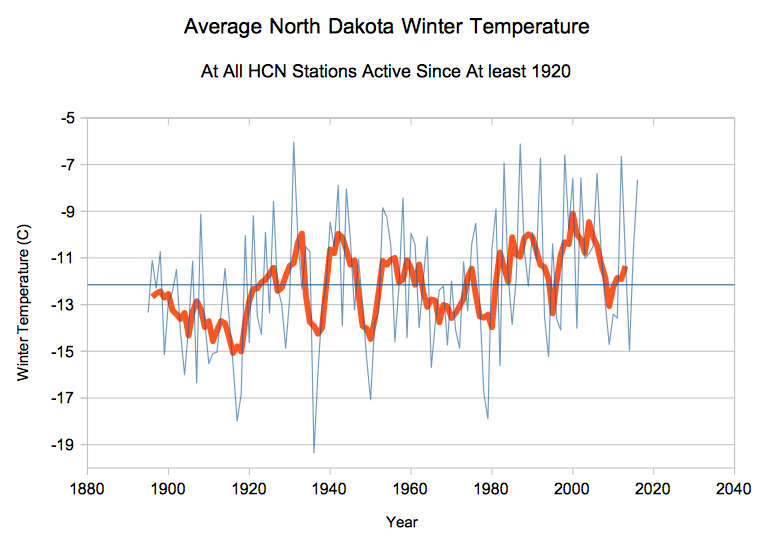
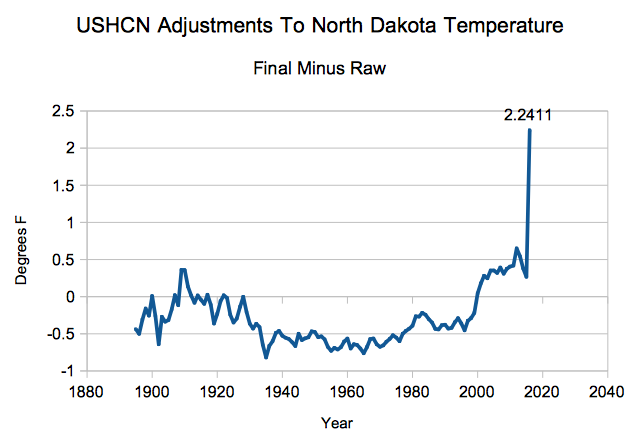
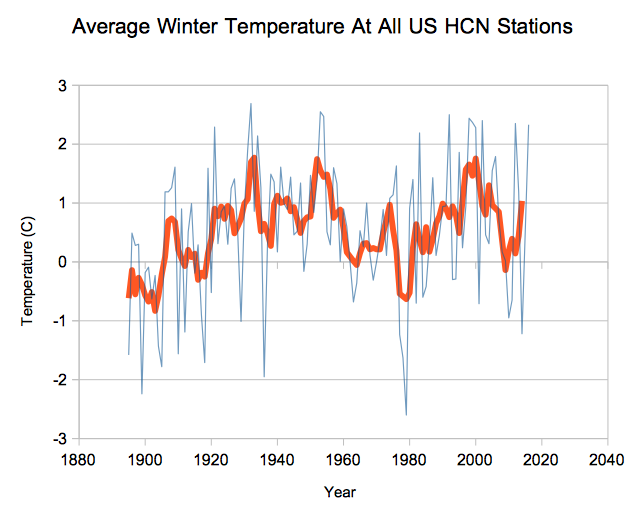
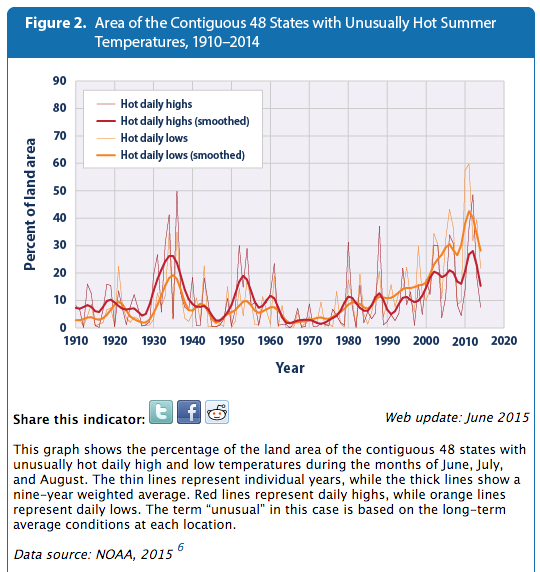
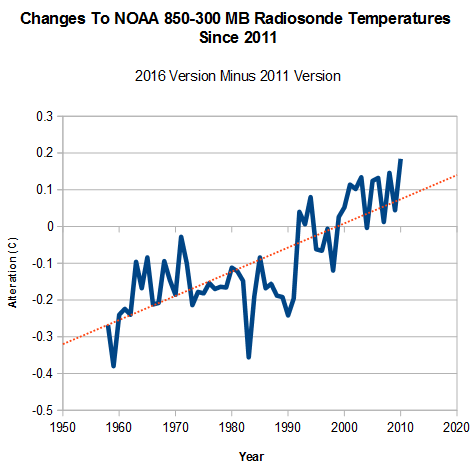
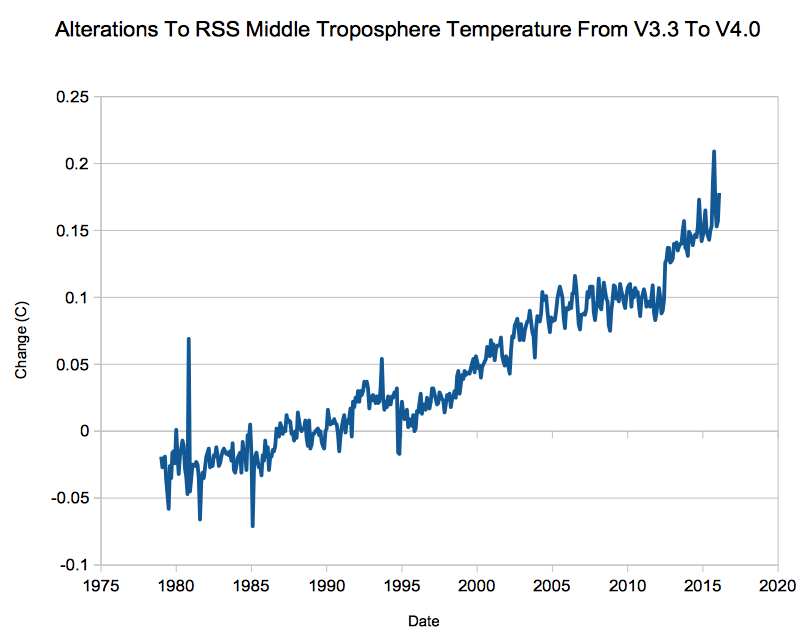
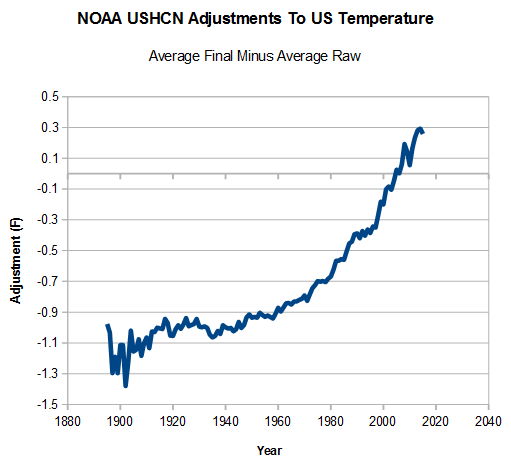
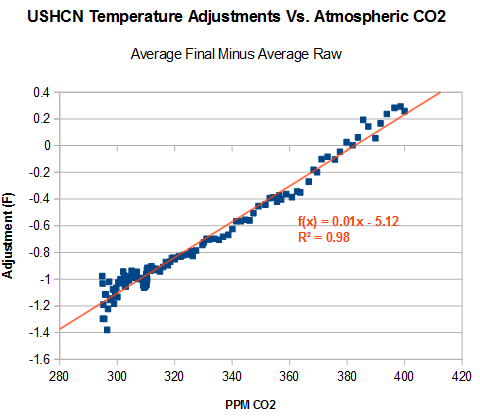
Suppose there are 20 things wrong with a data set, and scientists correct only the 10 problems which reduce warming. Even on the odd chance that the 10 corrections were done legitimately, they have completely corrupted the data set. And you end up with a mess like this.






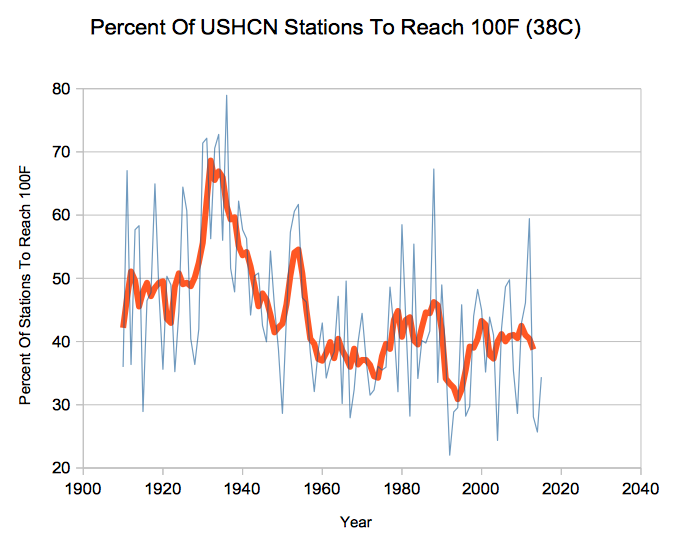
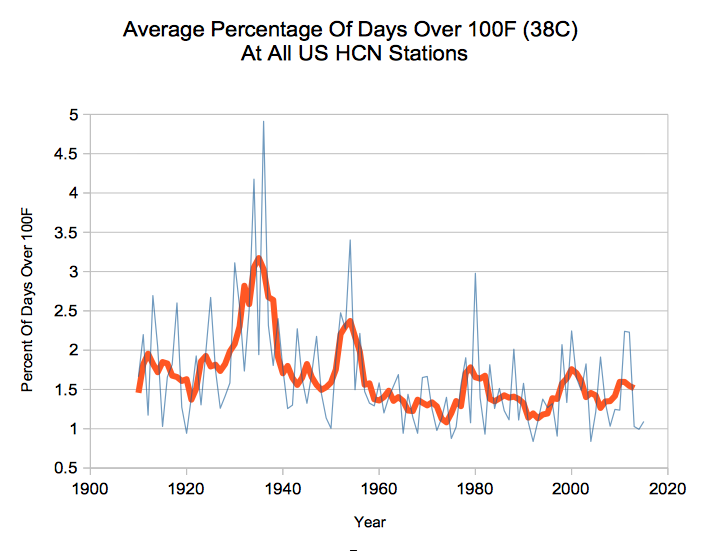
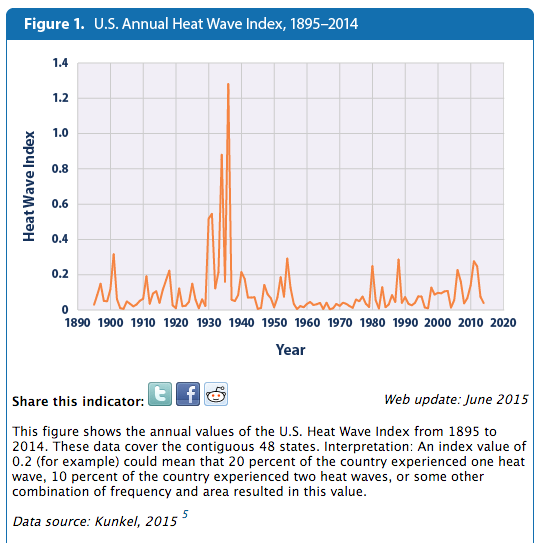
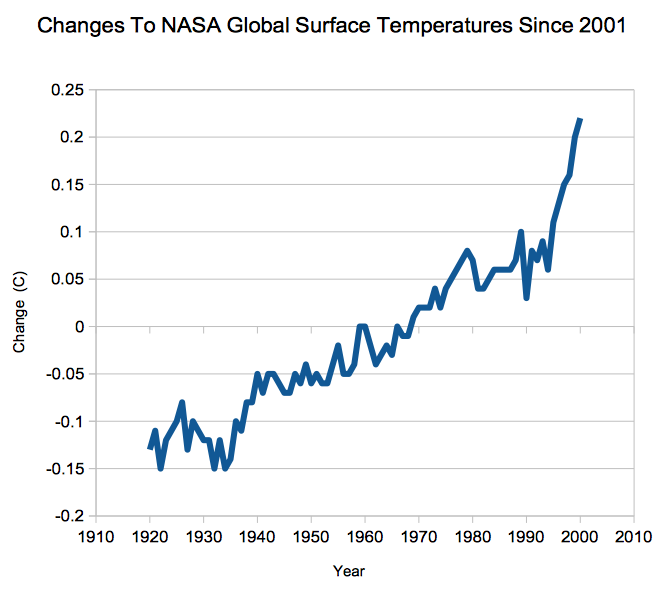

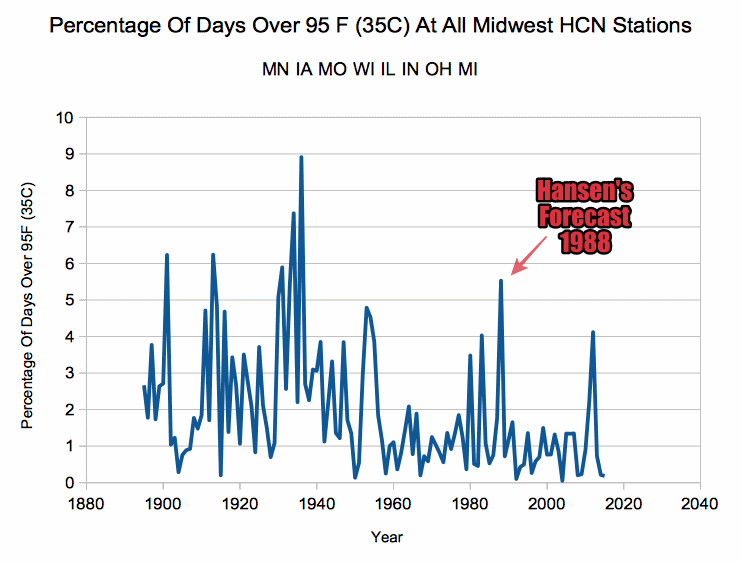
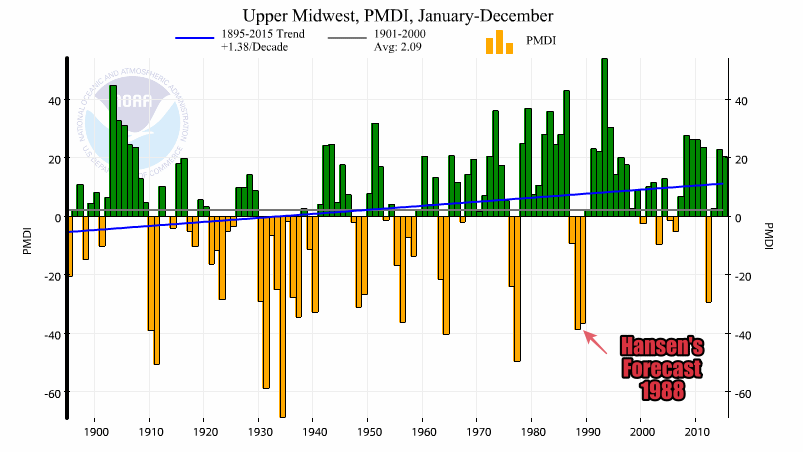
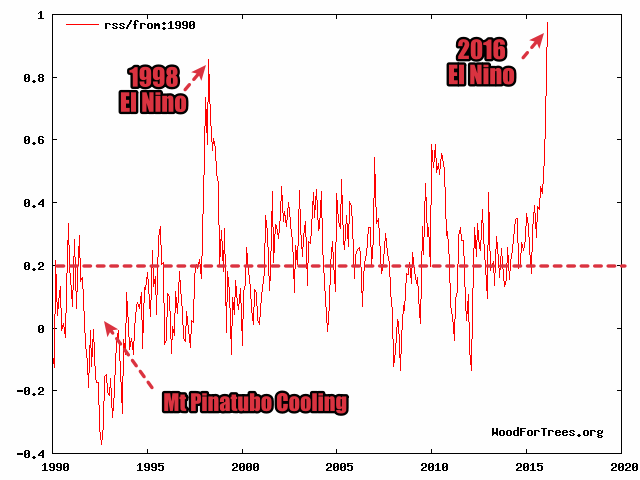
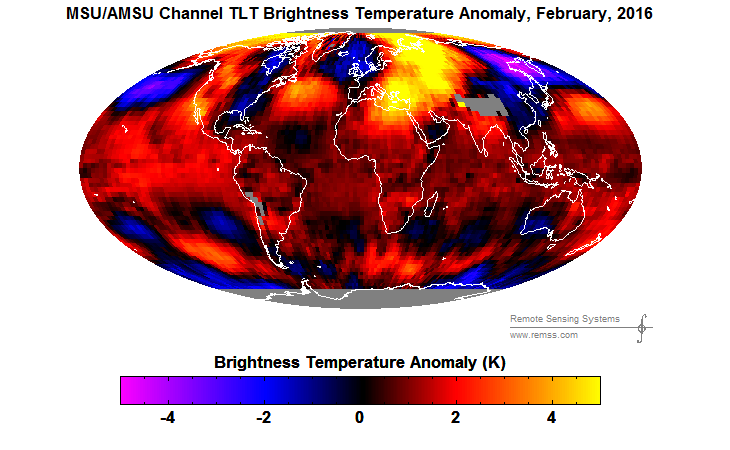
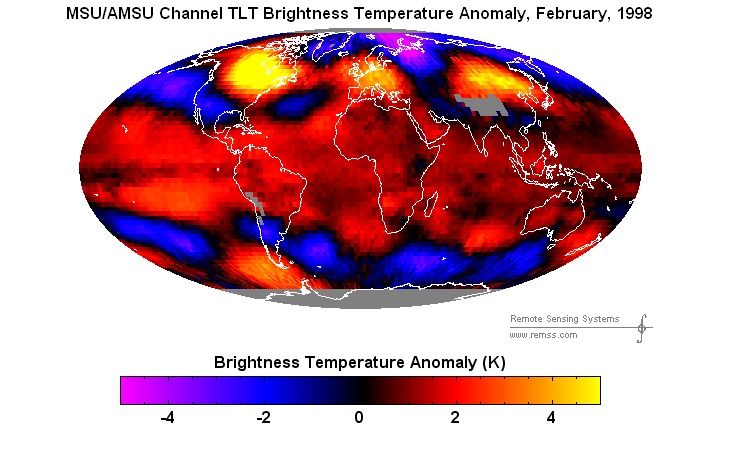
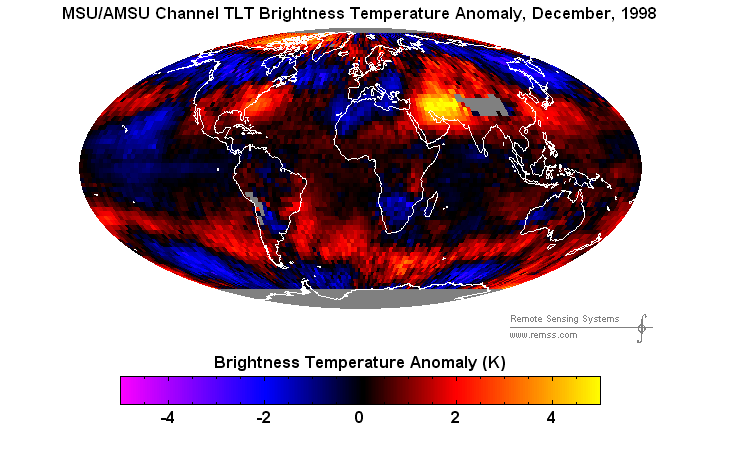

{kind=link}