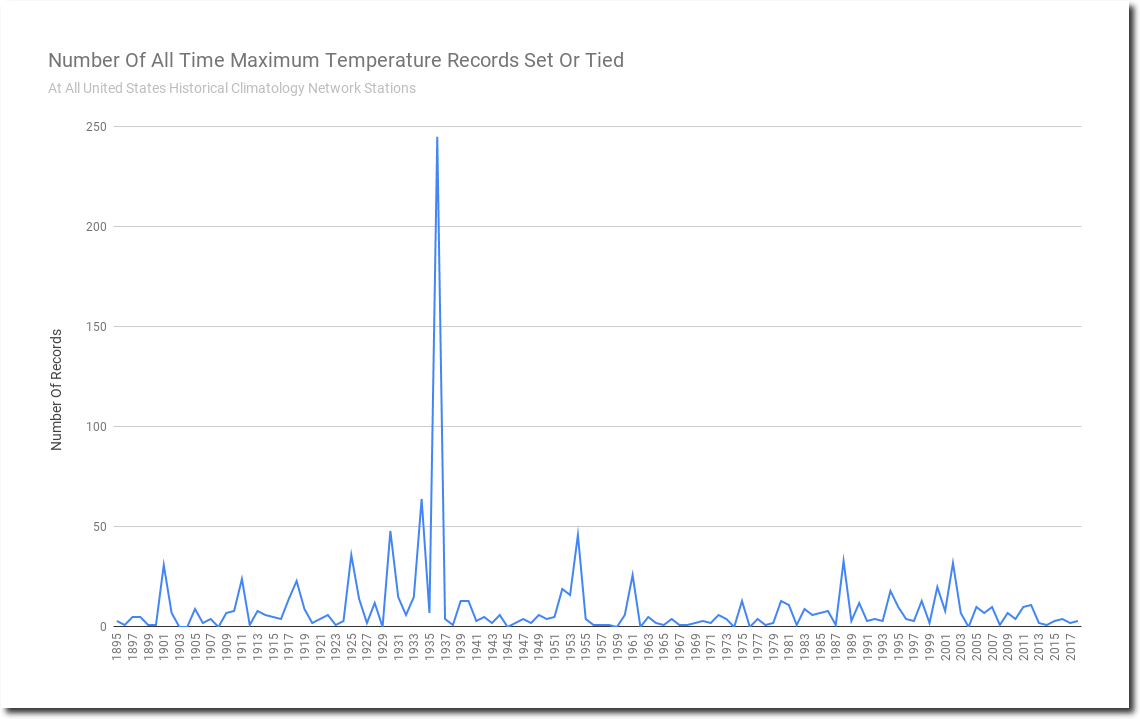
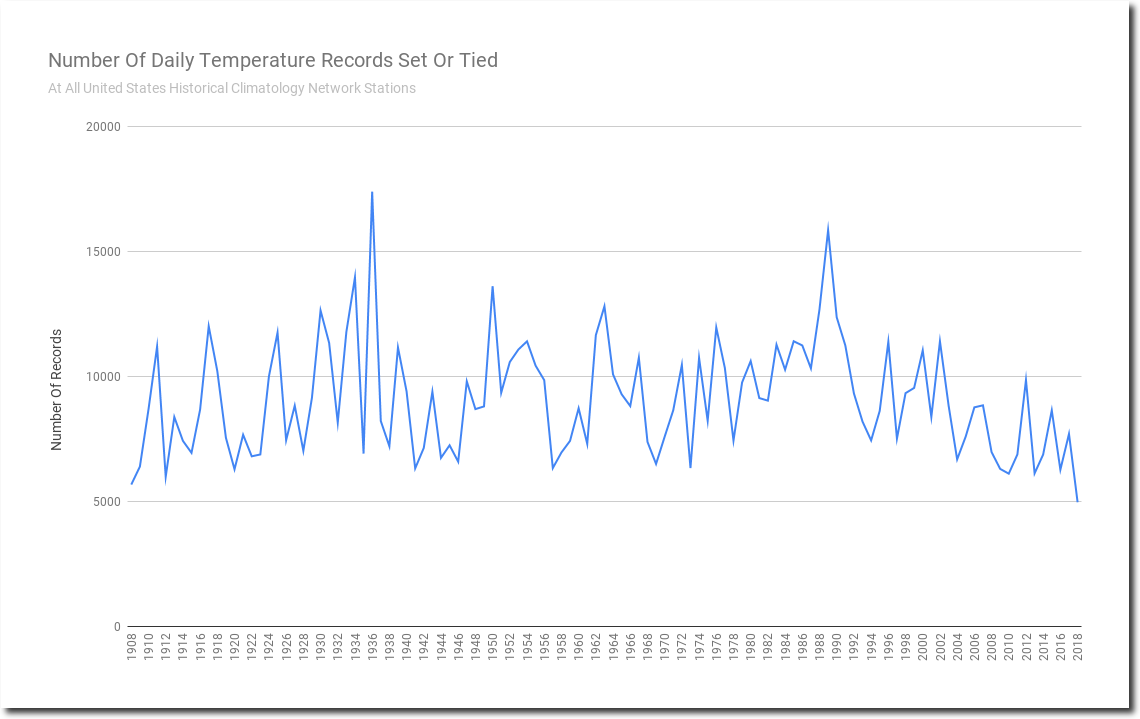
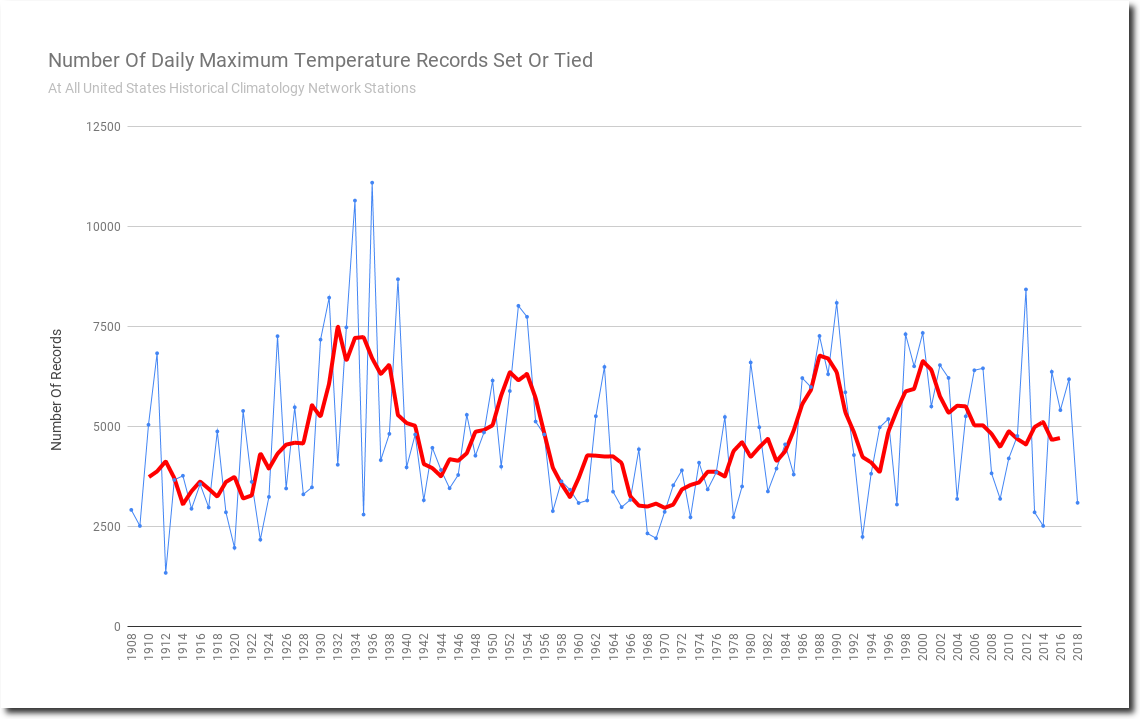
Every time I post a graph showing temperature records, all kinds of wild theories are made claiming that early years show more records simply because they are early. This is complete nonsense. The algorithm below is the basis of the counting.
max = -1000.0
max_year_list = []
for year in range(1895, 2018) :
if (temperature[year] > max) :
# Start a new list if the old record is beaten
max_year_list = [year]
max = temperature[year]
else if (temperature[year] == max) :
# Append to the list if the old record is tied
max_year_list.append(year)
The only way a record gets counted is if it is highest temperature from 1895-2018.