
July, 1936 was about 15 degrees hotter than July, 2017 in the Midwest. The animation below shows the daily maximum temperatures at all Midwest USHCN stations during both years.
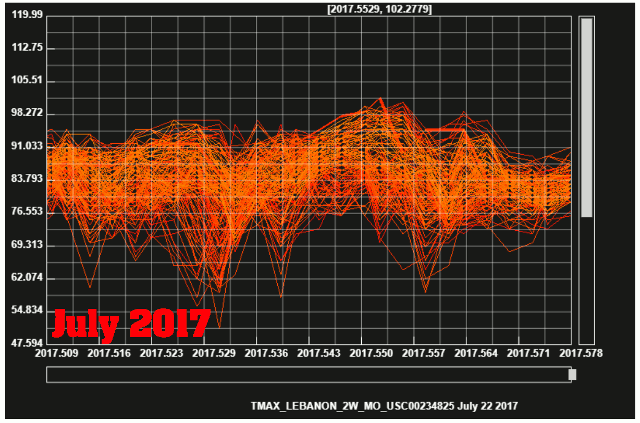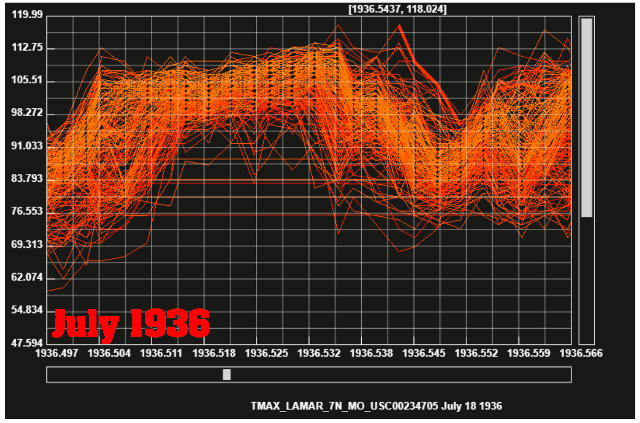
July, 1936 was about 15 degrees hotter than July, 2017 in the Midwest. The animation below shows the daily maximum temperatures at all Midwest USHCN stations during both years.
